Learning Similarities - Part 1
I am writing this blog to chronicle my activities and progress as I go about my project for Google Summmer of Code(GSOC), 2018.
Introduction to my project, Similarity Learning with Neural Networks:
Similarity Learning tries to develop a function which can measure the similarity between two objects. For example, given two questions, what is the likelihood that they are the same or given a question-answer pair, what is the similarity between them. The advantage of these models is that they abstract the internal representations of their inputs and provide outputs as a simple cosine similarity value between the vectors of its inputs. Several Similarity Learning models exist, but considering the recent success of deep learning techniques, the project is focusing mainly on the Neural Network based models.
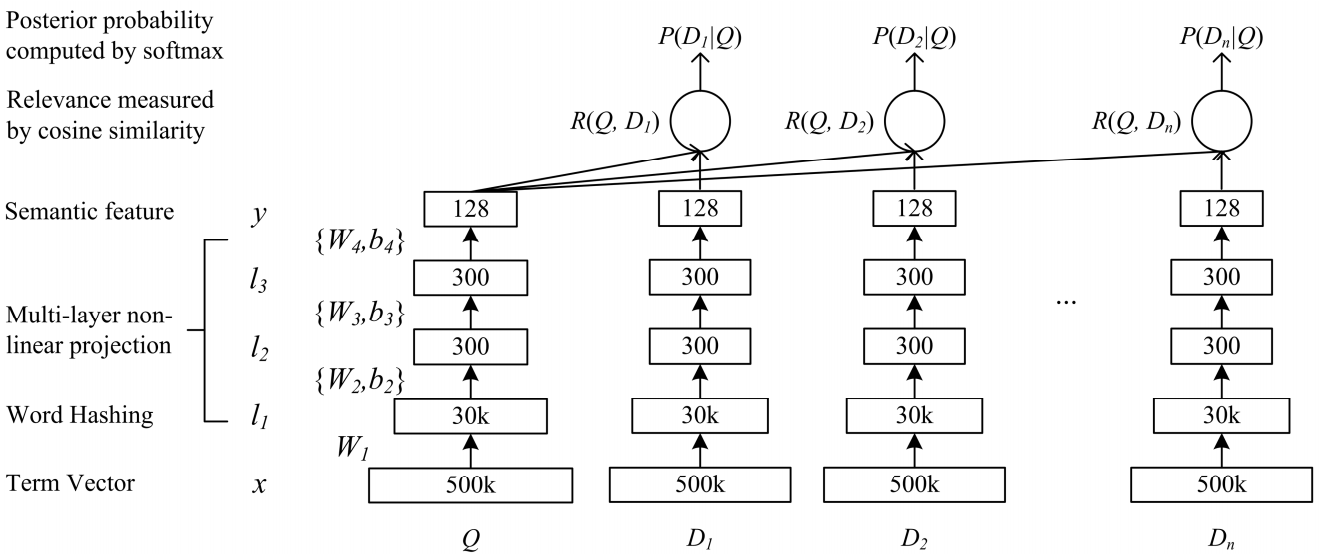
Community Bonding Period:
I utilized the Community Bonding period to develop the easiest model I could find in my list of SL models, Deep Structured Semantic Model (DSSM). Luckily, my work was made a lot easier by this awesome repository, MatchZoo, which has implemented a lot of models and benchmarked them. In fact, MatchZoo was a big influence in my proposal for GSOC. Writing the code for extracting data from the datasets and training a simple model gave me a good feel for the things ahead. The code for this can be found in this PR.
First 2 weeks of GSOC:
The first meeting I had with my mentors, Ivan Menshikh and Mandar Deshpande, set a clear idea for what was needed to be done:
I have to build a script which can evaluate the "goodness" of any given model and then work on developing the best model based on the evaluations made by this script.
This goodness can be measured in terms of metrics like Mean Average Precision(MAP), Normalized Discounted Cumulative Gain(nDCG), etc.
Although MatchZoo had already released scripts to evaluate these metrics and their corresponding benchmarks, it was necessary to cross check it on my own machine. Unfortunately, not all the benchmarks were getting reproduced. For example, some of the outputs I got were half of what they had published. I quickly opened an issue on their repo and they've gone about fixing the bug.
This exercise, however, made me question the credibility of any code not written by me. Ivan had insisted from the beginning that I make my own script and I finally realized the need for it.
The next few days went in understanding the metrics involved in evaluating the models and the corresponding code in MatchZoo. I needed a script which would give in query data, get the results and grade them through the metrics. It was made a bit more challenging because I had to translate my data to a format the model understands.
The Evaluation script should do the following:
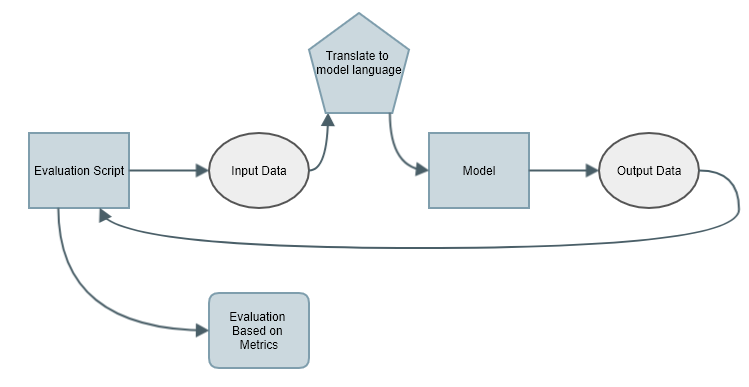
Since each model has it's own way of representing the data, we need to translate the data format for it to understand. For example, my input data is "hello world", but the model might have a word-int dicitonary which will translate it to [45, 32]
After digging through some more MatchZoo code, I realized that they are saving their outputs in a file after running on the test data. This meant, I can directly take their outputs and run my scripts! They were saving the output in the TREC(Text REtrival Conference) format and I wrote a script which went through it and scored it. Fortunately, my results and the MatchZoo results were quite close.
It was also decided that as a control case, we will bench mark unsupervised algorithms like word2vec and doc2vec. Word2Vec gave okayish results while doc2vec gave fabulous results! In fact, doc2vec was too good to be true. Only later did I realize that I had trained and tested the model on the same dataset! This small mistake on my side could have lead to some inconsistent results later. I am glad that I caught it early, fear that there are more bugs like it and pray that I find them if they exist.
Week 3:
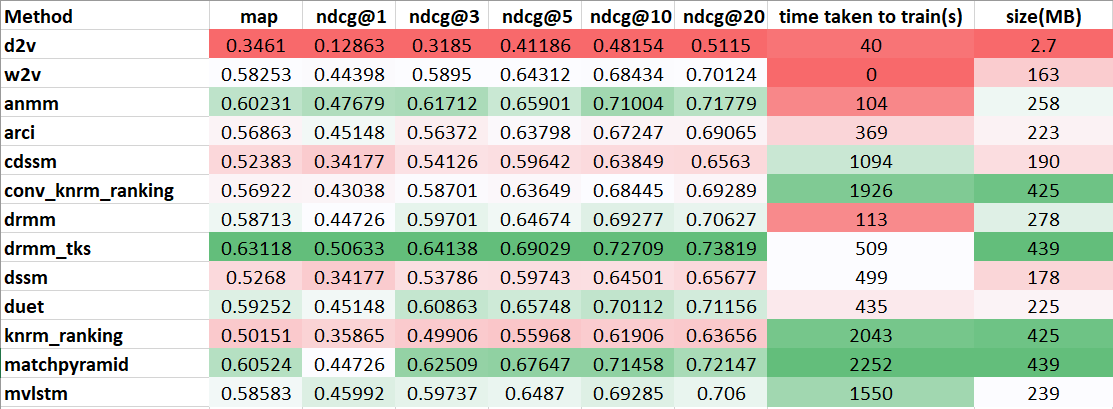
At this point, I had a full bench marking of all the models using my evaluation script whose results are shown below. This presents a good list of models to implement and tune. In deciding which model to use, we checked their metrics scores, time taken to train and memory required. From the current data, it looks like DRMM_TKS gives the best results with acceptable time-to-train and memory. In this week, I will go about implementing this model.
Week 4:
Currently, I have built and trained the drmm_tks model which scores a results close to those of MatchZoo. The remaining time will now be spent tuning the model parameters, adding more models and presenting an easy interface to use. Hopefully, I will be able to add evaluations on more datasets.
My Thoughts and Conclusion:
The last few weeks have been intense! It has been up and down with me getting stuck on some parts and then having a sudden breakthrough. The project is definitely interesting and could be very useful for people who work in this space. I just hope I am able to keep an acceptable pace and do it justice. I look forward to the next few weeks!