Learning Similarities - Part 3
Approach
Before implementing any models, we decided to set up an evaluation pipeline. Evaluating the models, however needed them to be implemented. Luckily, we have a repository, MatchZoo, which had the models implemented. Although, the repo was providing its own evaluation metrics, they couldn’t be trusted. So, we set up our evaluation script which can be found in my Evaluation Repo. The script basically gets the output in the TREC format and evaluates it.
Based on these results:
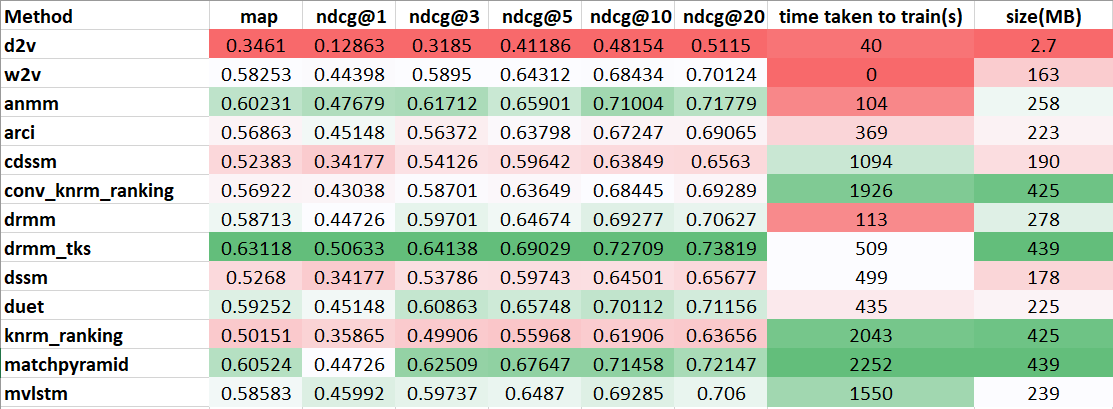
We decided to implement DRMM_TKS model since it gave the best results.
Unfortunately, at the time, it didn’t cross my mind to evaluate the 300 dimensional word vectors. (The evaluation you see is for 50 dims. I made the naive assumption that the numbers will be similar irrespective of dims). Later inspection revealed that 300 dim glove vectors gets 0.62 MAP.
Moreover, the way of implementing MAP was probably a bit wrong. Below is a table of a newer evaluation with proper metrics. More on evaluations can be found at the ending sections.
| WikiQA test set | w2v 50 dim | w2v 100 dim | w2v 200 dim | w2v 300 dim | MatchPyramid | FT 300 dim | DRMM_TKS |
|---|---|---|---|---|---|---|---|
| map | 0.6016 | 0.6148 | 0.6285 | 0.6277 | 0.6406 | 0.6199 | 0.6311 |
| gm_map | 0.4642 | 0.4816 | 0.4972 | 0.4968 | 0.5041 | 0.4763 | 0.4928 |
| Rprec | 0.4318 | 0.4551 | 0.4709 | 0.4667 | 0.4918 | 0.4715 | 0.4752 |
| bpref | 0.4251 | 0.4457 | 0.4613 | 0.456 | 0.4886 | 0.4642 | 0.4768 |
| recip_rank | 0.6147 | 0.628 | 0.6419 | 0.6373 | 0.6471 | 0.6336 | 0.6401 |
| iprec_at_recall_0.00 | 0.6194 | 0.6322 | 0.6469 | 0.6437 | 0.6543 | 0.6375 | 0.6447 |
| iprec_at_recall_0.10 | 0.6194 | 0.6322 | 0.6469 | 0.6437 | 0.6543 | 0.6375 | 0.6447 |
| iprec_at_recall_0.20 | 0.6194 | 0.6322 | 0.6469 | 0.6437 | 0.6543 | 0.6375 | 0.6447 |
| iprec_at_recall_0.30 | 0.6146 | 0.6269 | 0.6431 | 0.6401 | 0.6505 | 0.6314 | 0.6447 |
| iprec_at_recall_0.40 | 0.6125 | 0.6269 | 0.6404 | 0.6394 | 0.6474 | 0.6293 | 0.6425 |
| iprec_at_recall_0.50 | 0.6125 | 0.6269 | 0.6404 | 0.6394 | 0.6474 | 0.6293 | 0.6425 |
| iprec_at_recall_0.60 | 0.5937 | 0.6068 | 0.6196 | 0.6219 | 0.6393 | 0.6115 | 0.6255 |
| iprec_at_recall_0.70 | 0.5937 | 0.6068 | 0.6196 | 0.6219 | 0.6393 | 0.6115 | 0.6255 |
| iprec_at_recall_0.80 | 0.5914 | 0.6039 | 0.6175 | 0.619 | 0.6368 | 0.6094 | 0.6216 |
| iprec_at_recall_0.90 | 0.5914 | 0.6039 | 0.6175 | 0.619 | 0.6368 | 0.6094 | 0.6216 |
| iprec_at_recall_1.00 | 0.5914 | 0.6039 | 0.6175 | 0.619 | 0.6368 | 0.6094 | 0.6216 |
| P_5 | 0.1893 | 0.1951 | 0.1967 | 0.1975 | 0.1984 | 0.1926 | 0.1959 |
| P_10 | 0.1107 | 0.1111 | 0.1119 | 0.114 | 0.1165 | 0.1119 | 0.114 |
| P_15 | 0.0774 | 0.0776 | 0.0787 | 0.0787 | 0.0787 | 0.0774 | 0.0785 |
| P_20 | 0.0595 | 0.0597 | 0.0597 | 0.0597 | 0.0599 | 0.0591 | 0.0597 |
| ndcg_cut_1 | 0.4403 | 0.4486 | 0.4691 | 0.4587 | 0.4938 | 0.4774 | 0.4876 |
| ndcg_cut_3 | 0.5867 | 0.6077 | 0.6213 | 0.626 | 0.6261 | 0.6033 | 0.6209 |
| ndcg_cut_5 | 0.6417 | 0.6598 | 0.6722 | 0.6743 | 0.6774 | 0.6593 | 0.6684 |
| ndcg_cut_10 | 0.6825 | 0.693 | 0.7055 | 0.7102 | 0.7228 | 0.6982 | 0.7108 |
| ndcg_cut_20 | 0.6993 | 0.7101 | 0.7208 | 0.7211 | 0.728 | 0.7115 | 0.7223 |
| Metric | Full form |
| map | Mean Average Precision |
| gmap | Geometric Mean Average Precision |
| Rprec | Reciprocal Precision |
| P_K | Precision at K |
| nDCG_cut_k | normalized discounted cumulative gain at cut k |
| iprec_at_recall_k | interpolated precision at standard recall level k |
| recip_rank | reciprocal rank |
A full description can be found here
GMAP is the geometric mean of per-topic average precision, in contrast with MAP which is the arithmetic mean. If a run doubles the average precision for topic A from 0.02 to 0.04, while decreasing topic B from 0.4 to 0.38, the arithmetic mean is unchanged, but the geometric mean will show an improvment.
Bpref is a preference-based information retrieval measure that considers whether relevant documents are ranked above irrelevant ones. It is designed to be robust to missing relevance judgments, such that it gives the same experimental outcome with incomplete judgments that Mean Average Precision would with complete judgments.
Datasets
About WikiQA
Wiki QA dataset consists of a query, doc, label pairs. You can download it here The general format is:
q1 d1_1 0
q1 d1_2 1
q1 d1_3 0
-------------
q2 d2_1 0
q2 d2_2 1
q2 d2_3 0
q2 d2_4 1
-------------
:
:
-------------
qn dn_1 0
qn dn_2 1
qn dn_3 0
Every query has a set of candidate documents which can be relevant or irrelevant to it. Sometimes, a query can have no relevant documents. We filter out such documents.
Here’s an example of the dataset:
| QuestionID | Question | DocumentID | DocumentTitle | SentenceID | Sentence | Label |
|---|---|---|---|---|---|---|
| Q1 | how are glacier caves formed? | D1 | Glacier cave | D1-0 | A partly submerged glacier cave on Perito Moreno Glacier . | 0 |
| Q1 | how are glacier caves formed? | D1 | Glacier cave | D1-1 | The ice facade is approximately 60 m high | 0 |
| Q1 | how are glacier caves formed? | D1 | Glacier cave | D1-2 | Ice formations in the Titlis glacier cave | 0 |
| Q1 | how are glacier caves formed? | D1 | Glacier cave | D1-3 | A glacier cave is a cave formed within the ice of a glacier . | 1 |
| Q1 | how are glacier caves formed? | D1 | Glacier cave | D1-4 | Glacier caves are often called ice caves , but this term is properly used to describe bedrock caves that contain year-round ice. | 0 |
| Q2 | How are the directions of the velocity and force vectors related in a circular motion | D2 | Circular motion | D2-0 | In physics , circular motion is a movement of an object along the circumference of a circle or rotation along a circular path. | 0 |
| Q2 | How are the directions of the velocity and force vectors related in a circular motion | D2 | Circular motion | D2-1 | It can be uniform, with constant angular rate of rotation (and constant speed), or non-uniform with a changing rate of rotation. | 0 |
| Q2 | How are the directions of the velocity and force vectors related in a circular motion | D2 | Circular motion | D2-2 | The rotation around a fixed axis of a three-dimensional body involves circular motion of its parts. | 0 |
| Q2 | How are the directions of the velocity and force vectors related in a circular motion | D2 | Circular motion | D2-3 | The equations of motion describe the movement of the center of mass of a body. | 0 |
| Q2 | How are the directions of the velocity and force vectors related in a circular motion | D2 | Circular motion | D2-4 | Examples of circular motion include: an artificial satellite orbiting the Earth at constant height, a stone which is tied to a rope and is being swung in circles, a car turning through a curve in a race track , an electron moving perpendicular to a uniform magnetic field , and a gear turning inside a mechanism. | 0 |
| Q2 | How are the directions of the velocity and force vectors related in a circular motion | D2 | Circular motion | D2-5 | Since the object’s velocity vector is constantly changing direction, the moving object is undergoing acceleration by a centripetal force in the direction of the center of rotation. | 0 |
| Q2 | How are the directions of the velocity and force vectors related in a circular motion | D2 | Circular motion | D2-6 | Without this acceleration, the object would move in a straight line, according to Newton’s laws of motion . | 0 |
WikiQA Statistics:
Split | Number of items Total Queries | 1242 Train Queries(80%) | 873 Test Queries(20%) | 263 Dev Queries(10%) | 126
About other datasets not used
The table below summarizes WikiQA and some other datasets like:
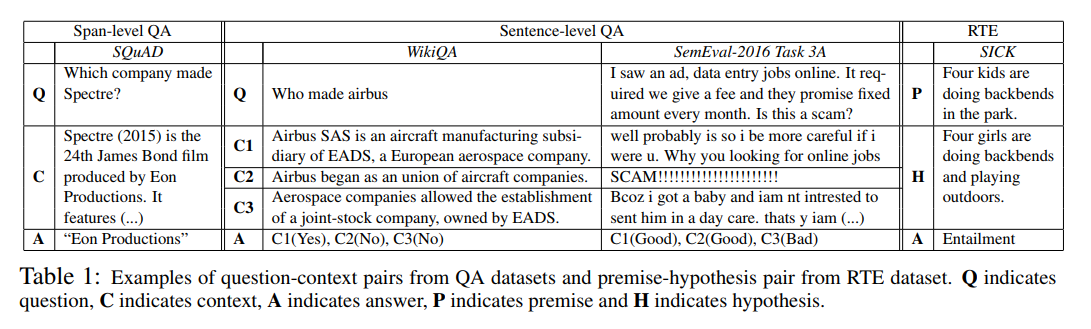
Why WikiQA
For the task of similarity learning, we are evaluating on the WikiQA Dataset. The MAP value of the WikiQA dataset shows a correlation across datasets. The idea was, do well on WikiQA and it should do well across different datasets. Also, we have an existing repo which had code and benchmarks written around WikiQA.
Establishing a baseline with w2v
First have to had to get a baseline to beat. We use the average of word vectors in a sentence to get the vector for a sentence/document.
"Hello World" -> (vec("Hello") + vec("World"))/2
When 2 documents are to be compared for similarity/relevance, we take the Cosine Similarity between them as the similarity. (300 dimensional vectors were seen to perform the best, so we chose them.)
The w2v 300 dim MAP score on the full set(100%) of WikiQA is 0.59 train split(80%) of WikiQA is 0.57 test split(20%) of WikiQA is 0.62 dev split(10%) of WikiQA is 0.62
DRMM TKS
The Deep Relevance Matching Model(Top K Solutions) is a variant of the DRMM model. Although it’s not published as a paper, the author of the paper released the code along with the DRMM code (which is a paper) in the MatchZoo repo. Our initial evaluation showed the best result of 0.65 MAP. However, after intensive parameter tuning, this value hasn’t been reached on our model. Our model manages to get a MAP score of 0.63 on the test set and 0.66 on the dev set. Link to Paper
MatchPyramid
This model performed second best in our evaluation and thus was implemented. It currently scores the best MAP of 0.65 on the test set Link to Paper
Initial Conclusion
The initial paper which Introduced WikiQA proposed a model CNN-Cnt which could get a MAP of 0.65 on it. It compared it with several other models and claimed best results. We thought this was the theoretical/SOTA MAP value and the w2v model itself does decently good on it(0.62)
(The test splits are same for our and their evaluation since they have themselves provided the train-dev-test split.)
Is such a scenario, is it worth gathering supervised data? This is the main question. Seeing this, we felt like it wasn’t really worth it and we should move onto some other work.
We decided to go through a few more datasets to make sure this low performance isn’t specific to the WikiQA dataset. For this, we considered this gist which shares a lot of papers and datasets in NLP. Going through the papers, my attention was caught by some of the MAP values suggested by the papers.
Bilateral Multi-Perspective Matching for Natural Language Sentences(BiMPM) paper shows a MAP of 0.71 on WikiQA. The BiMPM paper cited another paper SequenceMatchSequence which claimed an even higher MAP of 0.74 on WikiQA.
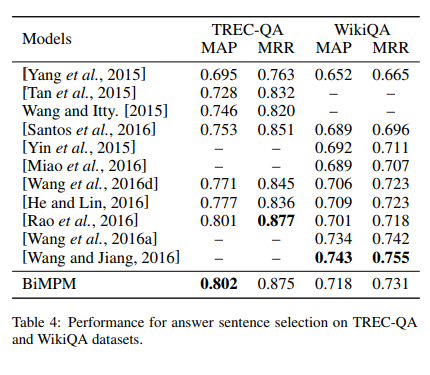
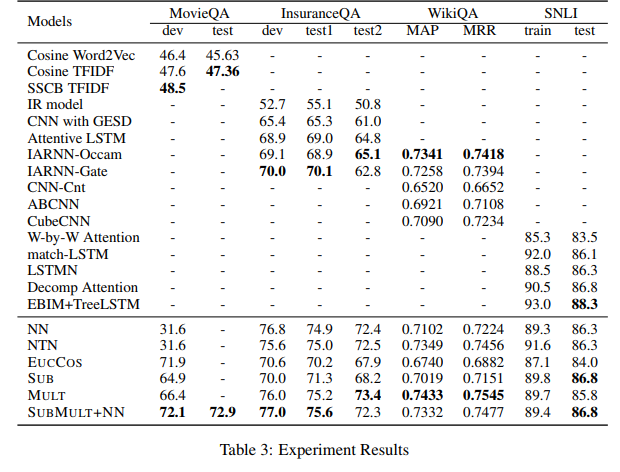
These are almost 1.2 more than our w2v baseline.
Since I found a partially implemented solution of BiMPM in a repository called MatchZoo, I went about implementing it. It is a very heavy model and needs GPU. Even with GPU, it takes 25 minutes for one epoch of 9000 samples. (I wonder if there would be any practical use of such a slow and heavy model.)
While my BiMPM model trained, I also looked through the SequenceMatchSequence paper and found that the author has provided a repo with the implementations and a docker image to ensure reproducability. However, it is written in lua and uses torch.
I also found a repo with the same code ported to pytorch. The author of this repo comments : “Author’s original repo reaches 0.734 (MAP) in Wikiqa Dev, and this code reaches 0.727 (MAP)” The author hasn’t mentioned which set’s score he reports in the paper. I assume, it’s the test set.
I tried reproducing the repository on my machine but there are some bugs in it. :(
There was an issue about MAP coming to 0.62 instead of 0.72 on dev set. The author commented:
I am afraid you are right. I used to reach ~72% via the given random seed on an old version of pytorch, but now with the new version of pytorch, I wasn’t able to reproduce the result. My personal opinion is that the model is neither deep or sophisticated, and usually for such kind of model, tuning hyper parameters will change the results a lot (although I don’t think it’s worthy to invest time tweaking an unstable model structure). If you want guaranteed decent accuracy on answer selection task, I suggest you take a look at those transfer learning methods from reading comprehension. One of them is here https://github.com/pcgreat/qa-transfer
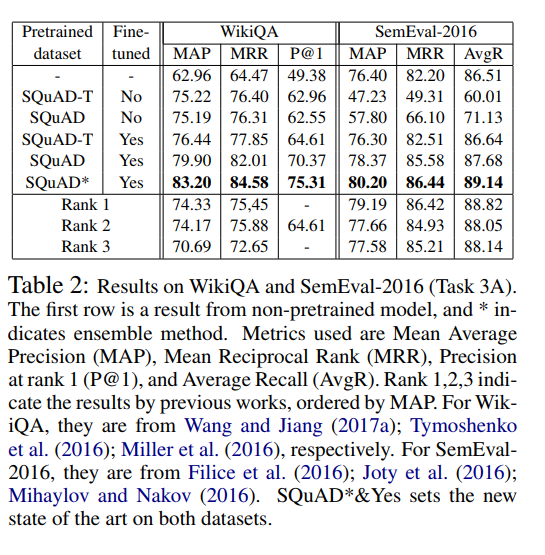
And thus, my hunt has lead me to the paper : Question Answering through Transfer Learning from Large Fine-grained Supervision Data which makes a crazier claim on MAP : 0.83
The paper’s author provides the implementation here in tensorflow. It might work, but after going through so many repos which claim to work, I am not so sure.
The author makes some notable claims in it’s abstract:
We show that the task of question answering (QA) can significantly benefit from the transfer learning of models trained on a different large, fine-grained QA dataset. We achieve the state of the art in two well-studied QA datasets, WikiQA and SemEval-2016 (Task 3A), through a basic transfer learning technique from SQuAD. For WikiQA, our model outperforms the previous best model by more than 8%. We demonstrate that finer supervision provides better guidance for learning lexical and syntactic information than coarser supervision, through quantitative results and visual analysis. We also show that a similar transfer learning procedure achieves the state of the art on an entailment task.
So, how this model works is It takes an existing model for QA called BiDirectional Attention Flow (BiDAF), which would take in a query and a context. It would then predict the range/span of words in the context which is relevant to the query. It was adapted to the SQUAD dataset.
Example of SQUAD:

The QA-Transfer takes the BiDAF net and chops off the last layer to make it more QA like, ie., something more like WikiQA:
q1 - d1 - 0
q1 - d2 - 0
q1 - d3 - 1
q1 - d4 - 0
They call this modified network BiDAF-T
Then, they take the SQUAD dataset and break the context into sentences and labels each sentence as relevant or irrelevant. This new dataset is called SQUAD-T
The new model, BiDAF-T is then trained on SQUAD-T. When this model is evaluated on WikiQA, it gets MAP : 0.75 They then take the train set of WikiQA and train BiDAF-T further. That’s when in gets MAP : 0.83
They call it Transfer Learning.
So, as such, it’s not exactly a new model. It’s just an old model(BiDAF), trained on a modified dataset and then used on WikiQA and SentEval. However, the model does suprisingly well on both of them. The author has provided their own repo.
Since there is a QA Transfer from SQUAD, it might not always work on non english words. In that case, it’s better to try an older method like BiMPM or SeqMatchSeq
At this point, I am mostly skeptical. But if it works, 0.62 of word2vec -> 0.83 (almost 0.21) seems pretty good.
I can only wonder if tomorrow, I will stumble upon a newer paper with 0.9!
Non ML related front
My gensim-like API is almost ready. It just needs a decently working model!
It has the following features:
- Saving
- Loading
- Online Training (needs a bit more checking)
- Metric Callbacks
- Streaming Support
Here’s a sample log of training the BiMPM model
2018-07-12 12:13:25,552 : INFO : 'pattern' package not found; tag filters are not available for English
2018-07-12 12:13:25,987 : INFO : loading projection weights from /home/aneeshyjoshi/gensim-data/glove-wiki-gigaword-50/glove-wiki-gigaword-50.gz
2018-07-12 12:13:44,624 : INFO : loaded (400000, 50) matrix from /home/aneeshyjoshi/gensim-data/glove-wiki-gigaword-50/glove-wiki-gigaword-50.gz
2018-07-12 12:13:44,624 : INFO : Starting Vocab Build
2018-07-12 12:13:45,139 : INFO : Vocab Build Complete
2018-07-12 12:13:45,139 : INFO : Vocab Size is 19890
2018-07-12 12:13:45,140 : INFO : Building embedding index using KeyedVector pretrained word embeddings
2018-07-12 12:13:45,140 : INFO : The embeddings_index built from the given file has 400000 words of 50 dimensions
2018-07-12 12:13:45,140 : INFO : Building the Embedding Matrix for the model's Embedding Layer
2018-07-12 12:13:45,220 : INFO : There are 740 words out of 19890 (3.72%) not in the embeddings. Setting them to random
2018-07-12 12:13:45,220 : INFO : Adding additional words from the embedding file to embedding matrix
2018-07-12 12:13:46,366 : INFO : Normalizing the word embeddings
2018-07-12 12:13:46,545 : INFO : Embedding Matrix build complete. It now has shape (400742, 50)
2018-07-12 12:13:46,545 : INFO : Pad word has been set to index 400740
2018-07-12 12:13:46,545 : INFO : Unknown word has been set to index 400741
2018-07-12 12:13:46,545 : INFO : Embedding index build complete
2018-07-12 12:13:46,580 : INFO : Input is an iterable amd will be streamed
__________________________________________________________________________________________________
2018-07-12 12:13:50,335 : INFO : Layer (type) Output Shape Param # Connected to
2018-07-12 12:13:50,335 : INFO : ==================================================================================================
2018-07-12 12:13:50,335 : INFO : doc (InputLayer) (None, 40) 0
2018-07-12 12:13:50,335 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,336 : INFO : query (InputLayer) (None, 40) 0
2018-07-12 12:13:50,336 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,336 : INFO : embedding_1 (Embedding) (None, 40, 50) 20037100 query[0][0]
2018-07-12 12:13:50,336 : INFO : doc[0][0]
2018-07-12 12:13:50,336 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,336 : INFO : doc_len (InputLayer) (None, 1) 0
2018-07-12 12:13:50,336 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,336 : INFO : query_len (InputLayer) (None, 1) 0
2018-07-12 12:13:50,336 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,336 : INFO : bi_lstm_1 (BiLSTM) [(None, 40, 140), (N 0 embedding_1[0][0]
2018-07-12 12:13:50,336 : INFO : embedding_1[1][0]
2018-07-12 12:13:50,336 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,336 : INFO : sequence_mask_2 (SequenceMask) (None, 40) 0 doc_len[0][0]
2018-07-12 12:13:50,336 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,336 : INFO : sequence_mask_1 (SequenceMask) (None, 40) 0 query_len[0][0]
2018-07-12 12:13:50,336 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,336 : INFO : multi_perspective_match_1 (Mult (None, 40, 250) 28000 bi_lstm_1[1][0]
2018-07-12 12:13:50,336 : INFO : bi_lstm_1[1][1]
2018-07-12 12:13:50,336 : INFO : sequence_mask_2[0][0]
2018-07-12 12:13:50,336 : INFO : bi_lstm_1[0][0]
2018-07-12 12:13:50,337 : INFO : bi_lstm_1[0][1]
2018-07-12 12:13:50,337 : INFO : sequence_mask_1[0][0]
2018-07-12 12:13:50,337 : INFO : bi_lstm_1[0][0]
2018-07-12 12:13:50,337 : INFO : bi_lstm_1[0][1]
2018-07-12 12:13:50,337 : INFO : sequence_mask_1[0][0]
2018-07-12 12:13:50,337 : INFO : bi_lstm_1[1][0]
2018-07-12 12:13:50,337 : INFO : bi_lstm_1[1][1]
2018-07-12 12:13:50,337 : INFO : sequence_mask_2[0][0]
2018-07-12 12:13:50,337 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,337 : INFO : bi_lstm_2 (BiLSTM) [(None, 40, 100), (N 0 multi_perspective_match_1[0][0]
2018-07-12 12:13:50,337 : INFO : multi_perspective_match_1[1][0]
2018-07-12 12:13:50,337 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,337 : INFO : concatenate_1 (Concatenate) (None, 200) 0 bi_lstm_2[0][1]
2018-07-12 12:13:50,337 : INFO : bi_lstm_2[1][1]
2018-07-12 12:13:50,337 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,337 : INFO : highway_1 (Highway) (None, 200) 80400 concatenate_1[0][0]
2018-07-12 12:13:50,337 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,337 : INFO : dropout_1 (Dropout) (None, 200) 0 highway_1[0][0]
2018-07-12 12:13:50,337 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,337 : INFO : dense_1 (Dense) (None, 1) 201 dropout_1[0][0]
2018-07-12 12:13:50,337 : INFO : ==================================================================================================
2018-07-12 12:13:50,338 : INFO : Total params: 20,145,701
2018-07-12 12:13:50,338 : INFO : Trainable params: 108,601
2018-07-12 12:13:50,338 : INFO : Non-trainable params: 20,037,100
2018-07-12 12:13:50,338 : INFO : __________________________________________________________________________________________________
2018-07-12 12:13:50,434 : INFO : Found 26 unknown words. Set them to unknown word index : 400741
2018-07-12 12:13:50,448 : INFO : Found 101 unknown words. Set them to unknown word index : 400741
Epoch 1/12
200/200 [==============================] - 331s 2s/step - loss: 0.8388 - acc: 0.3481
2018-07-12 12:19:33,859 : INFO : MAP: 0.58
2018-07-12 12:19:33,863 : INFO : nDCG@1 : 0.40
2018-07-12 12:19:33,868 : INFO : nDCG@3 : 0.59
2018-07-12 12:19:33,872 : INFO : nDCG@5 : 0.64
2018-07-12 12:19:33,877 : INFO : nDCG@10 : 0.69
2018-07-12 12:19:33,881 : INFO : nDCG@20 : 0.69
Epoch 2/12
200/200 [==============================] - 326s 2s/step - loss: 0.7811 - acc: 0.37841;3D
2018-07-12 12:25:06,113 : INFO : MAP: 0.58
2018-07-12 12:25:06,118 : INFO : nDCG@1 : 0.40
2018-07-12 12:25:06,122 : INFO : nDCG@3 : 0.58
2018-07-12 12:25:06,127 : INFO : nDCG@5 : 0.63
2018-07-12 12:25:06,131 : INFO : nDCG@10 : 0.69
2018-07-12 12:25:06,136 : INFO : nDCG@20 : 0.69
Epoch 3/12
200/200 [==============================] - 327s 2s/step - loss: 0.7491 - acc: 0.3710
2018-07-12 12:30:38,413 : INFO : MAP: 0.61
2018-07-12 12:30:38,417 : INFO : nDCG@1 : 0.46
2018-07-12 12:30:38,422 : INFO : nDCG@3 : 0.61
2018-07-12 12:30:38,426 : INFO : nDCG@5 : 0.66
2018-07-12 12:30:38,431 : INFO : nDCG@10 : 0.71
2018-07-12 12:30:38,435 : INFO : nDCG@20 : 0.72
Epoch 4/12
200/200 [==============================] - 326s 2s/step - loss: 0.7460 - acc: 0.3932
2018-07-12 12:36:10,651 : INFO : MAP: 0.62
2018-07-12 12:36:10,655 : INFO : nDCG@1 : 0.46
2018-07-12 12:36:10,660 : INFO : nDCG@3 : 0.62
2018-07-12 12:36:10,664 : INFO : nDCG@5 : 0.67
2018-07-12 12:36:10,669 : INFO : nDCG@10 : 0.72
2018-07-12 12:36:10,673 : INFO : nDCG@20 : 0.72
Epoch 5/12
200/200 [==============================] - 326s 2s/step - loss: 0.7355 - acc: 0.3640
2018-07-12 12:41:42,642 : INFO : MAP: 0.62
2018-07-12 12:41:42,646 : INFO : nDCG@1 : 0.48
2018-07-12 12:41:42,650 : INFO : nDCG@3 : 0.62
2018-07-12 12:41:42,655 : INFO : nDCG@5 : 0.67
2018-07-12 12:41:42,659 : INFO : nDCG@10 : 0.72
2018-07-12 12:41:42,664 : INFO : nDCG@20 : 0.72
Epoch 6/12
200/200 [==============================] - 326s 2s/step - loss: 0.7409 - acc: 0.3601
2018-07-12 12:47:14,979 : INFO : MAP: 0.61
2018-07-12 12:47:14,983 : INFO : nDCG@1 : 0.44
2018-07-12 12:47:14,988 : INFO : nDCG@3 : 0.62
2018-07-12 12:47:14,992 : INFO : nDCG@5 : 0.67
2018-07-12 12:47:14,997 : INFO : nDCG@10 : 0.71
2018-07-12 12:47:15,001 : INFO : nDCG@20 : 0.72
Epoch 7/12
200/200 [==============================] - 326s 2s/step - loss: 0.7284 - acc: 0.3744
2018-07-12 12:52:47,034 : INFO : MAP: 0.62
2018-07-12 12:52:47,039 : INFO : nDCG@1 : 0.47
2018-07-12 12:52:47,043 : INFO : nDCG@3 : 0.62
2018-07-12 12:52:47,047 : INFO : nDCG@5 : 0.66
2018-07-12 12:52:47,052 : INFO : nDCG@10 : 0.72
2018-07-12 12:52:47,057 : INFO : nDCG@20 : 0.72
Epoch 8/12
200/200 [==============================] - 327s 2s/step - loss: 0.7218 - acc: 0.3861
2018-07-12 12:58:19,376 : INFO : MAP: 0.63
2018-07-12 12:58:19,380 : INFO : nDCG@1 : 0.48
2018-07-12 12:58:19,385 : INFO : nDCG@3 : 0.63
2018-07-12 12:58:19,389 : INFO : nDCG@5 : 0.69
2018-07-12 12:58:19,394 : INFO : nDCG@10 : 0.73
2018-07-12 12:58:19,398 : INFO : nDCG@20 : 0.73
Epoch 9/12
200/200 [==============================] - 326s 2s/step - loss: 0.7167 - acc: 0.3806
2018-07-12 13:03:51,447 : INFO : MAP: 0.63
2018-07-12 13:03:51,452 : INFO : nDCG@1 : 0.48
2018-07-12 13:03:51,456 : INFO : nDCG@3 : 0.63
2018-07-12 13:03:51,460 : INFO : nDCG@5 : 0.68
2018-07-12 13:03:51,465 : INFO : nDCG@10 : 0.72
2018-07-12 13:03:51,469 : INFO : nDCG@20 : 0.73
Epoch 10/12
200/200 [==============================] - 326s 2s/step - loss: 0.7256 - acc: 0.3883
2018-07-12 13:09:23,654 : INFO : MAP: 0.63
2018-07-12 13:09:23,659 : INFO : nDCG@1 : 0.48
2018-07-12 13:09:23,663 : INFO : nDCG@3 : 0.63
2018-07-12 13:09:23,668 : INFO : nDCG@5 : 0.68
2018-07-12 13:09:23,672 : INFO : nDCG@10 : 0.72
2018-07-12 13:09:23,677 : INFO : nDCG@20 : 0.73
Epoch 11/12
200/200 [==============================] - 326s 2s/step - loss: 0.7202 - acc: 0.3880
2018-07-12 13:14:55,811 : INFO : MAP: 0.62
2018-07-12 13:14:55,815 : INFO : nDCG@1 : 0.48
2018-07-12 13:14:55,820 : INFO : nDCG@3 : 0.62
2018-07-12 13:14:55,824 : INFO : nDCG@5 : 0.67
2018-07-12 13:14:55,829 : INFO : nDCG@10 : 0.72
2018-07-12 13:14:55,833 : INFO : nDCG@20 : 0.72
Epoch 12/12
200/200 [==============================] - 326s 2s/step - loss: 0.7186 - acc: 0.3909
2018-07-12 13:20:27,924 : INFO : MAP: 0.62
2018-07-12 13:20:27,929 : INFO : nDCG@1 : 0.47
2018-07-12 13:20:27,933 : INFO : nDCG@3 : 0.63
2018-07-12 13:20:27,938 : INFO : nDCG@5 : 0.68
2018-07-12 13:20:27,942 : INFO : nDCG@10 : 0.72
2018-07-12 13:20:27,947 : INFO : nDCG@20 : 0.73
Test set results
2018-07-12 13:20:28,170 : INFO : Found 21 unknown words. Set them to unknown word index : 400741
2018-07-12 13:20:28,200 : INFO : Found 264 unknown words. Set them to unknown word index : 400741
2018-07-12 13:20:40,185 : INFO : MAP: 0.57
2018-07-12 13:20:40,193 : INFO : nDCG@1 : 0.44
2018-07-12 13:20:40,202 : INFO : nDCG@3 : 0.57
2018-07-12 13:20:40,211 : INFO : nDCG@5 : 0.64
2018-07-12 13:20:40,221 : INFO : nDCG@10 : 0.68
2018-07-12 13:20:40,230 : INFO : nDCG@20 : 0.69
2018-07-12 13:20:40,232 : INFO : saving BiMPM object under test_bimpm, separately None
2018-07-12 13:20:40,232 : INFO : storing np array 'vectors' to test_bimpm.word_embedding.vectors.npy
2018-07-12 13:20:40,593 : INFO : storing np array 'embedding_matrix' to test_bimpm.embedding_matrix.npy
2018-07-12 13:20:41,235 : INFO : not storing attribute model
2018-07-12 13:20:41,235 : INFO : not storing attribute _get_pair_list
2018-07-12 13:20:41,235 : INFO : not storing attribute _get_full_batch_iter
2018-07-12 13:20:41,235 : INFO : not storing attribute queries
2018-07-12 13:20:41,235 : INFO : not storing attribute docs
2018-07-12 13:20:41,235 : INFO : not storing attribute labels
2018-07-12 13:20:41,235 : INFO : not storing attribute pair_list
2018-07-12 13:20:42,237 : INFO : saved test_bimpm
As can be seen, model seems to be doing a lot worse than the claimed 0.71 But at this point, I can’t tell if I that’s the model’s fault or a fault in my implementation. With 20 minutes per epoch, it’s a bit tough to tune.
This brings me to my next topic:
Evaluation Metrics
The chief metrics chosen here is Mean Average Precision(MAP). There seem to be varying implementations of it. Above, you can see the results of my implementation which can be found here
There is a competing implementation by TREC which is a standard for IR system evaluations. TREC provided a binary to evaluate your results as long as you put them in a cerain format. All reported Metrics are from TREC. Usually, my metrics and TREC have results which are about 0.03 apart but not always. For example, in the above example, my metrics say 0.57 MAP but TREC says 0.4 MAP.
Evaluation Method
All my evaluations are done by one script
It simply loads the model and makes it predict a similarity between 2 sentences/documents. The similarity is stored in the TREC format. It is well documented and it should be easy to understand on a first glance.
Final Conclusion
The final questions which needs answering is: How much increase in MAP is enough to justify a new model?
Potentially, 0.2 seems like a good estimate in which case, it QA-Transfer seems like a good bet. I am still skeptical if it will work If 0.1 we can try BiMPM or SeqMatchSeq.
My Personal Thoughts
Training and Tuning these models has been pretty cumbersome. There is a huge train time and often negligible changes. Many of the models don’t do as well and it’s pretty hard to point out the exact problem. I am putting in all my time and yet there is no significant progress in the last few days. I call this phase Parameter Tuning Hell. It’s hard to explain to others what work you have done because there is no “progress”. But progress in this tuning isn’t a function of time and effort or is it? In a Software Dev task, it would be easier to measure progress as “this module is done” and problems can be pin pointed and solutions mostly found on Stack Overflow. While building models, I make the model but it doesn’t work. I try changing this and that, but I if the model doesn’t do better, what can I do?
What I think we should do
QA-Transfer seems to be pretty recent and might be a good way to go ahead.