Datasets for Similarity Learning
Dataset Description for Similarity Learning
| Dataset Name | Link | Suggested Metrics | Some Papers that use the dataset | Brief Description |
|---|---|---|---|---|
| WikiQA |
|
|
Question-Candidate_Answer1_to_N-Relevance1_to_N | |
| SQUAD 2.0 | Website |
|
QA-Transfer(for pretraining) | Question-Context-Answer_Range_in_context |
| Quora Duplicate Question Pairs |
|
Accuracy, F1 |
|
Q1-Q2-DuplicateProbablity |
| Sem Eval 2016 Task 3A | genism-data(semeval-2016-2017-task3-subtaskA-unannotated) |
|
QA-Transfer(SQUAD* MAP=80.2, MRR=86.4, P@1=89.1) |
Question-Comment-SimilarityProbablity |
| MovieQA | Accuracy | SeqMatchSeq(SUBMULT+NN test=72.9%, dev=72.1%) |
Plot-Question-Candidate_Answers | |
| InsuranceQA | Website | Accuracy | SeqMatchSeq(SUBMULT+NN test1=75.6%, test2=72.3%, dev=77%) |
Question-Ground_Truth_Answer-Candidate_answer |
| SNLI | Accuracy |
|
Text-Hypothesis-Judgement | |
| TRECQA |
|
BiMPM(MAP:0.802, MRR:0.875) | Question-Candidate_Answer1_to_N-relevance1_to_N | |
| SICK | Website | Accuracy | QA-Transfer(Acc=88.2) | sent1-sent2-entailment_label-relatedness_score |
More dataset info can be found at the SentEval repo.
Links to Papers:
Some useful examples
SQUAD

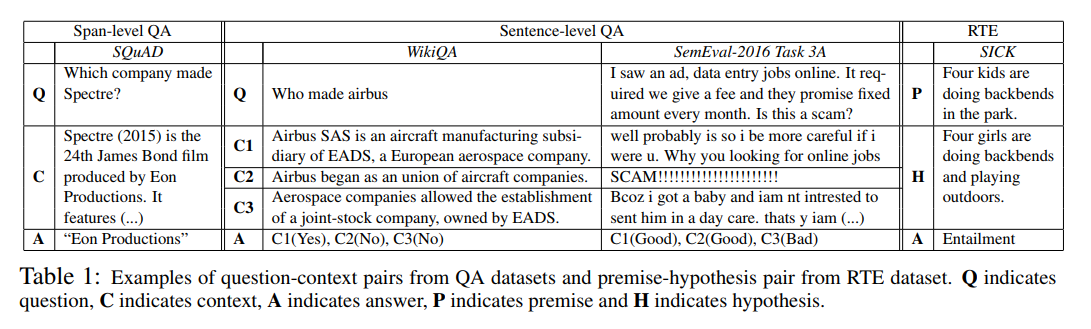
SQUAD, WikiQA, SemEval, SICK
MovieQA and InsuranceQA
